The showyourwork.yml config file#
This is the configuration file for showyourwork!, allowing you to customize several aspects of the workflow. Below is a list of all available options.
cache_on_zenodo#
Type: bool
Description: Flag controlling whether or not caching on Zenodo/Zenodo Sandbox
should be performed. Set this to false to disable caching.
Required: no
Default: true
Example:
cache_on_zenodo: true
dag#
Type: mapping
Description: Settings controlling the generation of an image of the article DAG (directed acyclic graph) that summarizes the dependencies among files in the workflow.
Required: no
Example:
dag:
render: true
dag.engine#
Type: str
Description: Graphviz layout engine. See options here.
Required: no
Default: sfdp
Example:
dag:
render: true
engine: sfdp
dag.graph_attr#
Type: mapping
Description: Custom attributes for the graph. See here for details. Note that all values must be provided as strings.
Required: no
Default:
ranksep: "1"
nodesep: "0.65"
Example:
dag:
render: true
graph_attr:
ranksep: "1"
nodesep: "0.65"
dag.group_by_type#
Type: bool
Description: Group files in the DAG by type? This will create plates for the figure scripts, datasets, figure outputs, etc.
Required: no
Default: false
Example:
dag:
render: true
group_by_type: true
dag.ignore_files#
Type: list
Description: List of files and/or patterns to ignore when drawing the article DAG.
Required: no
Default: []
Example:
dag:
render: true
ignore_files:
- src/tex/orcid-ID.png
- src/scripts/*.jl
dag.node_attr#
Type: mapping
Description: Attributes for all the nodes in the graph. See here for details. Note that all values must be provided as strings.
Required: no
Default:
shape: "box"
penwidth: "2"
width: "1"
Example:
dag:
render: true
node_attr:
shape: "box"
penwidth: "2"
width: "1"
dag.render#
Type: bool
Description: Render the article DAG (directed acyclic graph) showing the
relationship between all the input and output files in the workflow. The
DAG is saved as the file dag.pdf at the root of the repository.
Required: no
Default: false
Example:
dag:
render: true
datasets#
Type: mapping
Description: A mapping declaring static datasets to be downloaded from Zenodo or Zenodo Sandbox. Nested under this keyword should be a sequence of mappings labeled by the deposit version DOIs of Zenodo or Zenodo Sandbox datasets. See below for details.
Required: no
Example:
The following block shows how to tell showyourwork! about two files,
TOI640b.json and KeplerRot-LAMOST.csv, each of which is hosted
on a Zenodo deposit with a different version DOI. Note that the user should
separately provide dependencies information for each of these
files, so showyourwork! knows which scripts require these files.
datasets:
10.5281/zenodo.6468327:
contents:
TOI640b.json: src/data/TOI640b.json
10.5281/zenodo.5794178:
contents:
KeplerRot-LAMOST.csv: src/data/KeplerRot-LAMOST.csv
See below for the syntax of the contents section of the datasets mapping.
datasets.<doi>#
Type: mapping
Description: The Zenodo or Zenodo Sandbox version DOI for the deposit.
Note
Zenodo makes a distinction between version DOIs and concept DOIs. Version DOIs are static, and tied to a specific version of a deposit (the way you’d expect a DOI to behave); this is what you should provide here. Concept DOIs, on the other hand, point to all versions of a given record, and always resolve to the latest version. Check out the sidebar on the web page for this sample deposit:
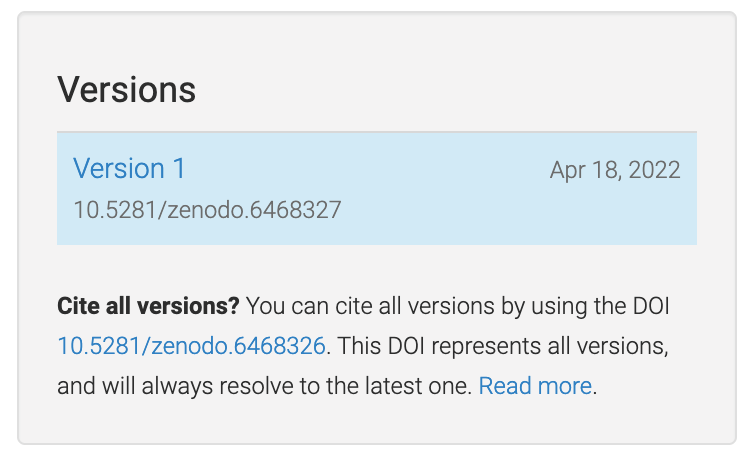
You can see that the DOI 10.5281/zenodo.6468327 corresponds to a specific version (1)
of the deposit, while the DOI 10.5281/zenodo.6468326 corresponds to all versions of
the deposit (it’s listed under “Cite all versions?”).
The former is a “version” DOI, while the latter is a “concept” DOI.
You can read more about that in the Zenodo docs.
Required: no
Example:
If the version DOI for a deposit containing the file TOI640b.json is 10.5281/zenodo.6468327,
we would specify the following in the config file:
datasets:
10.5281/zenodo.6468327:
contents:
TOI640b.json: src/data/TOI640b.json
See below for the syntax of the contents section of the datasets mapping.
datasets.<doi>.contents#
Type: mapping
Description: Specifies a mapping between files in a Zenodo or Zenodo Sandbox deposit and local
files. The contents field must contain key-value pairs of the form
remote-file: path-to-local-file
where remote-file is the name of the file on the remote (the Zenodo deposit)
and path-to-local-file is the path to the file on disk, relative to the
top level of the repository. The path-to-local-file may be omitted, in which
case the file name is preserved and the file is downloaded to the default
destination (see the option of the same name below).
If the remote file is a zipfile or a tarball, instead of a local path, users may provide a directory tree mapping that specifies the contents of the tarball and where they should be extracted to. The workflow will automatically extract them. See the example below for details.
Note
The contents section need only specify files used by the workflow; if
there are additional files in the Zenodo deposit that are not needed by
the workflow, they need not be listed. However, files that required by
the workflow must be listed explicitly; glob syntax is not allowed.
Required: no
Example:
The following example shows all the various ways in which Zenodo files can be downloaded, extracted, and mapped to local files:
datasets:
10.5281/zenodo.6468327:
destination: src/data/TOI640 # default folder to extract files to
contents:
README.md: # auto extracted to `src/data/TOI640/README.md`
TOI640b.json: src/data/TOI640/planet.json # rename the extracted file, just for fun
images.tar.gz: # remote tarballs behave like folders w/ same name
README.md: # auto extracted to `src/data/TOI640/images/README.md`
S06: # subfolder
image.json: src/data/TOI640/S06.json # rename and change destination folder
S07: # subfolder
image.json: src/data/TOI640/S07.json # rename and change destination folder
lightcurves.tar.gz: # another tarball
lightcurves: # files are nested inside `lightcurves` in this tarball
README.md: # auto extracted to `src/data/TOI640/lightcurves/lightcurves/README.md`
S06: # subfolder
lc.txt: src/data/TOI640/S06.txt # rename and change destination folder
S07: # subfolder
lc.txt: src/data/TOI640/S07.txt # rename and change destination folder
Recall that users must separately provide dependency information for each of these files via the dependencies key.
datasets.<doi>.destination#
Type: str
Description: The default destination to extract the contents of the Zenodo deposit to.
Required: no
Default: src/data
Example:
The following will extract all files in the Zenodo deposit with doi 10.5281/zenodo.6468327
to src/data (subfolders will be preserved).
datasets:
10.5281/zenodo.6468327:
destination: src/data
dependencies#
Type: list
Description: List of dependencies for each script. Each entry should be
the path to a script (either a figure script or the TeX manuscript itself)
relative to the repository root. Following each entry, provide a list of
all files on which the script depends. These dependencies may either be
static (such as helper scripts) or programmatically generated (such as
datsets downloaded from Zenodo). In the latter case, instructions on how
to generate them must be provided elsewhere (either via the zenodo key
below or via a custom rule in the Snakefile). In both cases, changes
to the dependency will result in a re-run of the section of the workflow that
executes the script.
Required: no
Default: []
Example:
Tell showyourwork! that the figure script my_figure.py depends on
the helper script utils/helper_script.py:
dependencies:
src/scripts/my_figure.py:
- src/scripts/utils/helper_script.py
You can also specify a dependency on a programmatically-generated file:
dependencies:
src/scripts/fibonacci.py:
- src/data/fibonacci.dat
provided data/fibonacci.dat is defined in a zenodo deposit (see below)
or instructions for generating it are provided in the Snakefile.
Finally, dependencies of the manuscript file are also allowed:
dependencies:
src/tex/ms.tex:
- src/tex/stylesheet.tex
margin_icons#
Type: mapping
Description: Define the color of the margin icons.
Required: no
Example:
margin_icons:
custom:
dataset: "0.5,0.2,0.6"
margin_icons.colors#
Type: mapping
Description: Allows custom colors to be set for the margin icons.
Required: no
margin_icons.colors.cache#
Type: str
Description: A string describing the desired rgb values for colour the Zenodo cache margin icon.
Required: no
margin_icons.colors.dataset#
Type: str
Description: A string describing the desired rgb values for colour the Zenodo dataset margin icon.
Required: no
margin_icons.colors.github#
Type: str
Description: A string describing the desired rgb values for colour the github margin icon.
Required: no
margin_icons.colors.sandbox#
Type: str
Description: A string describing the desired rgb values for colour the Zenodo Sandbox cache margin icon.
Required: no
margin_icons.horizontal_offset#
Type: int
Description: This defines the horizontal offset to be used for all of the margin icons (this helps with positioning in two-column documents). Negative values will move the icons left and positive values move right.
Required: no
margin_icons.monochrome#
Type: bool
Description: Makes all margin_icons black, this will override any custom colors.
Required: no
margin_icons:
monochrome: false
ms_name#
Type: str
Description: The name of the main TeX manuscript (without the path or the extension). Change this if you’d prefer to
name your manuscript something other than ms. Note that you should still
keep it in the src/tex directory. Note also that the compiled PDF file will
have the same name (e.g., ms_name: article will compile src/tex/article.tex and generate article.pdf
in the repository root) .
Required: no
Default: ms
Example:
ms_name: article
optimize_caching#
Type: bool
Description: Optimize the workflow graph by removing unnecessary jobs upstream
of cache hits? Can in some cases significantly reduce computation time;
see here
for a detailed discussion. Snakemake does not do this optimization, so it is implemented
as a patch on the showyourwork side and therefore disabled by default.
Required: no
Example:
optimize_caching: true
overleaf#
Type: mapping
Description: Settings pertaining to Overleaf integration. See below for details, and make sure to check out Overleaf integration.
Required: no
Example:
overleaf:
id: 62150dd16134ef045f81d1c8
push:
- src/tex/figures
pull:
- src/tex/ms.tex
- src/tex/bib.bib
overleaf.gh_actions_sync#
Type: bool
Description: Commit and push Overleaf changes to the GitHub remote when running on GitHub Actions?
Default: true
Required: no
Example:
overleaf:
gh_actions_sync: true
overleaf.id#
Type: str
Description: The id of the Overleaf project to integrate with. This can be obtained from the URL of the project, e.g.:
https://www.overleaf.com/project/6262c032aae5421d6d945acf
in this case, the id is 6262c032aae5421d6d945acf.
Warning
Please read the Overleaf integration docs before manually adding/changing this value, as you could risk losing changes to your local document or to your Overleaf document the next time you build!
Required: no
Example:
overleaf:
id: 62150dd16134ef045f81d1c8
overleaf.pull#
Type: bool
Description: A list of files and/or folders to be pulled from the Overleaf project before every build. These should be files that are only ever modified on Overleaf, such as the TeX manuscript and other TeX files. Paths should be relative to the top level of the repository. Exact names are required; no glob syntax allowed.
Required: no
Default: []
Example:
overleaf:
pull:
- src/tex/ms.tex
- src/tex/bib.bib
overleaf.push#
Type: bool
Description: A list of files and/or folders to be pushed to the Overleaf project after every build. These should be files that are programmatically generated by the build, such as the figure files. Paths should be relative to the top level of the repository. Exact names are required; no glob syntax allowed.
Required: no
Default: []
Example:
overleaf:
push:
- src/tex/figures
require_inputs#
Type: bool
Description: If there is no valid rule to generate a given output file
(because of, e.g., a missing input file), but the output file itself is present on disk,
Snakemake will not by default raise an error. This can be useful for running
workflows locally, but it can compromise the reproducibility of a workflow when
a third party attempts to run it. Therefore, the default behavior in showyourwork!
is to require all output files to be programmatically generatable when running
the workflow, even if the output files exist on disk already. Otherwise, an
error is thrown. Set this option to false to override this behavior.
Required: no
Default: true
Example:
require_inputs: true
run_cache_rules_on_ci#
Type: bool
Description: Allow cacheable rules to run on GitHub Actions if the cached
output is not available? Default is false, which prevents potentially
computationally expensive rules from running on the cloud. In this case,
cache misses result in an error when running on GitHub Actions only.
Required: no
Default: false
Example:
run_cache_rules_on_ci: false
scripts#
Type: mapping
Description: Mapping of script extensions to instructions on how to execute
them to generate output. By default, showyourwork! expects output files
(e.g., figures or datasets) to
be generated by executing the corresponding scripts with python. You can add custom
rules here to produce output from scripts with other extensions, or change
the behavior for executing python scripts (such as adding command line
options, for instance). Each entry under scripts should be a file extension,
and under each one should be a string specifying how to generate the output file
from the input script. The following placeholders are recognized by showyourwork!
and expand as follows at runtime:
{script}: The full path to the input script.{output}: The full path to the output file (i.e., the generated figure). If the script generates more than one file, this expands to a space-separated list of outputs.{datasets}: A space-separated list of all the Zenodo datasets required by the current script.{dependencies}: A space-separated list of all the dependencies (including datasets) of the current script.
Required: no
Default: The default behavior for python scripts corresponds to the
following specification in the yaml file:
scripts:
py:
python {script}
That is, python is used to execute all scripts that end in .py.
Example: We can tell showyourwork! how to generate figures by executing a Jupyter notebook as follows:
scripts:
ipynb:
jupyter execute {script}
stamp#
Type: mapping
Description: Mapping controlling the display of the showyourwork! stamp on the title page.
Required: no
Example:
stamp:
enabled: true
stamp.angle#
Type: float
Description: The stamp rotation angle in degrees.
Required: no
Default: -20.0
Example:
stamp:
angle: -20.0
stamp.enabled#
Type: bool
Description: If false, will not display the stamp on the rendered PDF.
Required: no
Default: true
Example:
stamp:
enabled: true
stamp.size#
Type: float
Description: The size (width) of the stamp in inches.
Required: no
Default: 0.75
Example:
stamp:
size: 0.75
stamp.xpos#
Type: float
Description: The absolute horizontal position of the stamp in inches, measured from the right edge of the page to the center of the stamp (values increase to the left).
Required: no
Default: 0.50
Example:
stamp:
xpos: 0.50
stamp.ypos#
Type: float
Description: The absolute vertical position of the stamp in inches, measured from the top edge of the page to the center of the stamp (values increase downward).
Required: no
Default: 0.50
Example:
stamp:
ypos: 0.50
stamp.url#
Type: mapping
Description: Options controlling the display of the article repository URL in the stamp.
Required: no
Example:
stamp:
url:
enabled: true
maxlen: 40
stamp.url.enabled#
Type: bool
Description: Whether or not to display the URL of the repository in the
stamp. If true, displays it along a circular arc on the outside of the
stamp.
Required: no
Default: false
Example:
stamp:
url:
enabled: true
stamp.url.maxlen#
Type: int
Description: The maximum length of the repository URL to be displayed in
the stamp. If the URL is longer than this value, it will be truncated with
... when displayed (this does not, of course, affect the actual hyperlink
URL).
Required: no
Default: 40
Example:
stamp:
url:
enabled: true
maxlen: 40
synctex#
Type: bool
Description: Enable SyncTeX when building the article? This generates a *.synctex.gz file that allows certain editors (like VSCode) to automatically sync locations in your manuscript with locations in the compiled PDF.
Default: true
Required: no
Example:
synctex: true
tectonic_args#
Type: list
Description: A list of additional command-line options to be passed directly to
tectonic when building the manuscript.
Default: []
Required: no
Example:
tectonic_args: ["-Z", "shell-escape", "-Z", "shell-escape-cwd=."]
to enable TeX shell escape functionality (allows the script to run
arbitrary commands within TeX; be careful as this could be a security hazard).
This is required to use the minted package for syntax highlighting of code
snippets. The shell-escape-cwd=. option lets showyourwork save outputs
of shell calls, whereas without this option they would be deleted (for example,
the minted cache).
preprocess_arxiv_script#
Type: str
Description: A script controlling the preprocessing of the manuscript for submission to the arXiv. This is the path to a custom preprocessing script to use. The script should be executable and accept a single argument; this argument will be the path to the contents of the arXiv tarball. This script can modify the contents of the tarball in place, before the contents are put into a .tar.gz archive for submission.
Required: no
Example:
The following example script preprocesses the manuscript to set up minted in a way that is compatible with the arXiv, by freezing the minted cache after the build is complete. It also switches xcolor to require the table option for compatibility with the LaTeX used on arXiv.
#!/bin/bash
pushd $1
sed -i ms.tex -e 's/finalizecache/frozencache/g'
sed -i ms.tex -e '/PassOptionsToPackage/d'
sed -i showyourwork.tex -e 's/RequirePackage{xcolor}/RequirePackage[table]{xcolor}/g'
popd
verbose#
Type: bool
Description: Enable verbose output? Useful for debugging runs. By default,
showyourwork! suppresses nearly all Snakemake output, sending it directly
to the log file (see Logging). Setting verbose: true results in all
Snakemake output being printed to the screen as well. Note that you can
crank up the verbosity even more by passing the --verbose argument to
snakemake build, which makes Snakemake itself more talkative.
Required: no
Default: false
Example:
verbose: true
version#
Type: str
Description: The version of the showyourwork! package used to create the
workflow. As of 0.4.0 this setting no longer has any effect on the build
process, as articles are now always compiled using the installed version of
showyourwork. However, to improve compatibility with previous versions of
the code, we recommend keeping this setting in your config file.